Automated stone artefacts classification using machine learning
Dr Joshua Emmitt, Research Fellow, Social Science; Sina Masoud-Ansari, Centre for eResearch; Dr Rebecca Phillipps, Senior Lecturer, Anthropology; Stacey Middleton, Masters, Anthropology; Prof Simon Holdaway, Assoc Deputy VC Research, Research Strategy and Integrity

Introduction
The ability to distinguish natural from human manufactured stone artifacts has a long history in archaeology. Methods intended to differentiate unmodified from modified objects have not developed significantly since those identified in the 20th century.
A variety of attribute based approaches are described but despite these, in both past and more recent studies, there is a continued reliance on the opinion of experts who are able to identify relevant attributes and therefore make determinations about the origin of these objects. This raises issues around access to such experts and consistency in the identifications these experts make.
Another set of issues concern the volume of material that needs to be identified. In many instances gravel sized rock clasts including those
Methods
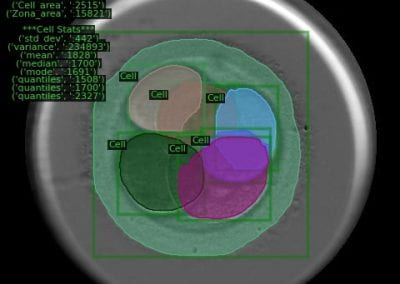
The Centre for eResearch developed the machine learning workflow for the automated classification system. This consisted of several components: training data generation, data preprocessing and model training. Training data was generated through expert labelling of approximately 6000 images of rocks and artefacts in various field and laboratory settings. The labels consisted of the object bounds, manually annotated by an archaeologist and the object classification (rock or artefact). The preprocessing step standardised the images and associated object bounding boxes to a 300×300 pixel format which was used to train a convolutional neural network (CNN) based object detection model. The model architecture was an openly available PyTorch implementation of the Faster R-CNN ResNet 50 which is designed to locate regions of interest in an image and generate a set of classification scores to rank the likelihood of a region matching a given class. Figure 1 summarises the object detection and classification process.
potentially showing anthropogenic or anthropoid modification are abundant, so separating classes of modified from unmodified material may involve large numbers of individual identifications. Our interest in differentiating stone artifacts from naturally occurring rocks relates to the abundance of rock clasts found in some archaeological sites. Stone artifacts are often the most abundant class of artifacts but their consistent identification is limited by the number of archaeologists with experience in their identification. The issues are compounded because many of the stone objects found come from commercial resource management projects that may lack the resources for detailed stone artifact identification. Here we report work intended to create a machine learning based technology for stone artifact identification as part of a solution to the lack of experts available to distinguish worked stone objects from naturally occurring clasts
Results
Model training took approximately 7 hours on an NVIDIA P40 GPU which was made available to us via the Nectar Research Cloud. The model was evaluated on a separate benchmark of approximately 1000 images which were selected to represent a range of stone artefact types. The benchmark images were also presented to expert archaeologists to compare against machine performance.
The trained model was able to achieve 100% accuracy on the benchmark images with a mean intersection over union (IoU) score of 0.82 where 1.0 indicates perfect alignment between predicted object bounds and the ground truth as determined by an expert. Two expert archaeologists were asked to classify the benchmark images and had classification accuracies of 99.4% and 94.8% respectively. The results suggest that automated detection of rocks and stone artefacts is possible and performs at near or above human expert performance on this task.

Figure 1: Object detection workflow. An input image 1) is preprocessed to a fixed size 2) with black pixel padding to meet the final dimensions. The model learns to identify potential object locations 3) which are used as input to a CNN 4) that learns feature combinations that distinguish one class from another. The final output is the region bounds and a classification e.g. rock or artefact 5).