Bayesian additive regression trees vs logistic regression – estimation of propensity scores
Samuel Passmore, Department of Statistics
Accurate comparison of hospital performance is crucial to the allocation of funding in New Zealand hospitals.
A problem for such comparisons is that patients and conditions are not randomly spread across hospitals. A range of factors, such as the economic environment surrounding the hospital, or a specialty unit within the hospital, mean that there may be disproportionate groups of demographics within any one hospital. When comparing hospitals’ performance, the non-random spread of patients can be accounted for through the use of propensity scores. Propensity scores weigh the importance of patients so that the demographics are balanced between hospitals. A number of methods can be used to estimate propensity scores.
My Honours project research compared the performance of Bayesian additive regression trees (BART) to a logistic regression. BART is a sum of trees model where the growth of a tree is constrained by its priors, then using an iterative Markov-chain Monte-Carlo algorithm, back fits the model for optimal fit. This method is computationally expensive.
Analysing propensity scores
Pan allowed me to run my analyses across 15 hospitals, with a sweep of parameter settings, in parallel. Considering a single run of a BART model would take between 10 –16 hours, being able to run this in parallel saved me weeks in time and allowed me to focus on the results of the analyses rather than waiting for the calculation to complete. For a project that only had a year time-frame this was very helpful. The staff at the Centre for eResearch were very helpful in helping me set up the analyses to run in the most efficient way which saved a lot of time and effort.
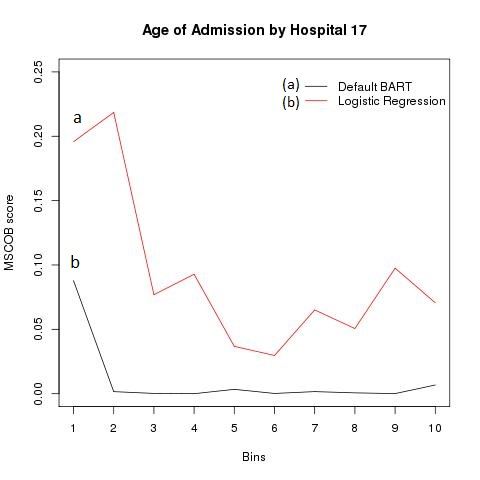
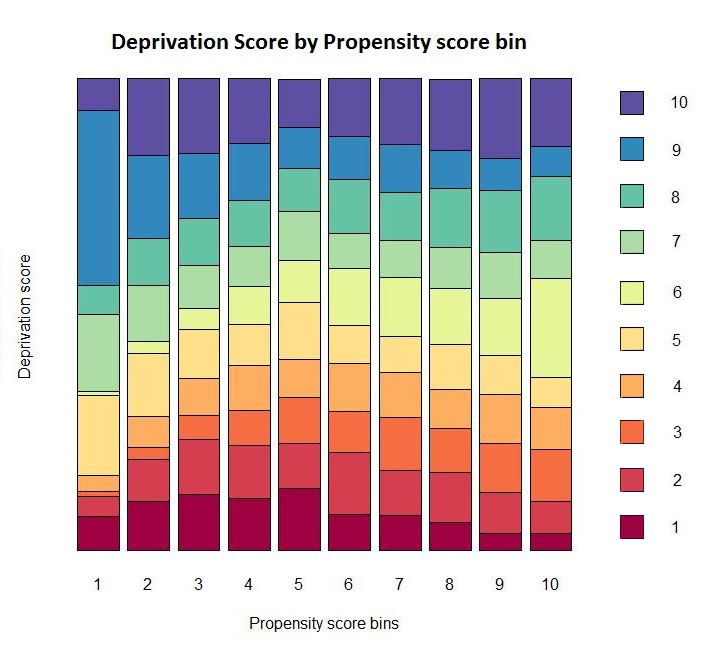
Figure 1: shows for hospital 17 the Mean Squared Covariate Balance score (MSCOB) for both the Default BART and Logistic regression models across the 10 propensity score bins. Propensity scores are continuous values from 0 – 1; however, to compare between hospitals we computed the mean-squared difference for each decile calling each a bin.