Using data mining for digital ink recognition
Rachel Blagojevic and Beryl Plimmer, Department of Computer Science
Computer-based diagramming is often cumbersome to achieve with typical mouse and keyboard input.
With recent advances in hardware, such as touch and stylus detection, computer-based sketch tools can offer a similar interaction experience to pen and paper. By imitating the pen and paper environment, sketch tools permit the quick construction of diagrams.
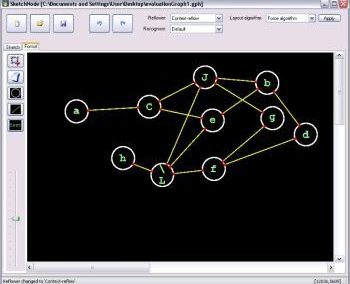
Automatic recognition of sketches enables benefits, such as the translation and execution of sketched models, and intelligent editing (see Figure 1). By developing more accurate recognisers, greater functionality can be supplied by computer-based sketch tools.
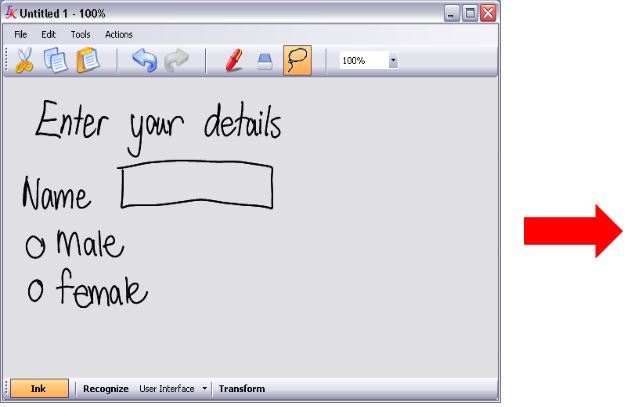
Figure 1: Benefits of automatic sketch recognition.
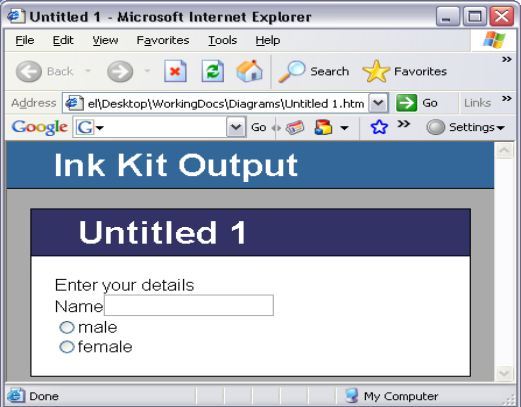
Automatic digital-ink diagram recognition technology is still inadequate for general use. Our research uses data mining techniques to improve the accuracy of recognition. As a challenging example that benefits from this approach, we have focused on the automatic separation of the writing and drawing components of diagrams. People are able to comprehend writing and drawing seamlessly, yet there is a clear semantic divide that suggests, from a computational perspective, that it is sensible to deal with them separately. Feature based recognition is a common approach to writing/drawing division. The choice of distinguishing features and algorithms is critical to its success. We have used data mining techniques to build more accurate writing /drawing dividers.

Figure 2 (above): Sketch recognition process with a writing-drawing divider.
The Pan cluster was used to perform our analysis of features and algorithms. The computational requirements of this analysis proved to be demanding, due to the complexity of the algorithms and the large number of features and instances included in the training data set. We had previously tried several hardware solutions, including standard desktop machines and several servers. However, when using these resources, many simple experiments took several days, or even weeks, to complete. In order to use the Pan cluster to its full capability, our experiments were distributed across several nodes. For example, for a ten-fold cross-validation trial, each fold was run in parallel by a separate cluster node. Parallelising the folds of each experiment greatly decreased the time required for the analysis, thereby allowing us to run more complex algorithms than before. Overall, excellent results were obtained from the cluster, which could not have been achieved otherwise. It enabled us to use large and varied datasets, ensuring that the levels of accuracy found were reliable and the algorithms were well trained. Our resulting dividers are significantly more accurate than three existing dividers.
Outcome
We have demonstrated that a systematic analysis of data mining techniques can significantly improve the accuracy of writing/drawing dividers. In the future, we plan to investigate how this methodology could be used to improve other parts of the recognition process for digital ink diagrams.